[deeplearning.ai] Convolution Neural Network

deeplearning.ai 코스의 네번째 수업 Convolution Neural Network(이하 CNN)이다. 컴퓨터 비전과 관련없는 일을 하고있지만 모르는것보단 낫지않은가..! 이참에 공부를해봐야겠다!
Padding
패딩을 안하고 컨볼루션을 진행할경우, 코너나 모서리에 있는 정보들이 유실되는 현상이 발생하여 패딩작업을 먼저 진행함
패딩 공식은
N - 인풋이미지 크기
F - 컨볼루션 커널 크기
기존 아웃풋 이미지 크기 공식 (N-F+1) * (N-F+1)
아웃풋 이미지가 인풋 이미지와 같은 크기가 나오게끔 패딩을 한다면, (N+2P-F+1) * (N+2P-F+1) 에 공식에서 P값을 구하면 얼마나 패딩을 해야하는지 계산이됨. 즉, N=6, F=3일때, 6+2P-3 + 1 = 6(인풋이미지 크기) 가 되니까, P는 1이되며. 즉 1만큼 패딩을 시켜주면된다. 그렇게된다면 인풋이미지는 8*8인 이미지로 변환하게되며, 이렇게되면 아웃풋이미지는 인풋이미지의 크기와 같이 6*6이 된다.
Valid Convolution
- No padding 기법, 인풋이미지가 컨볼루션을 거치면 이미지 크기가 줄어드는 기법
Same Convolution
- Padding 기법, 아웃풋 이미지가 인풋이미지와 같은 사이즈가 되게끔 인풋이미지를 패딩하는 방법
Strided Convolution
Stride라는 변수를 추가하여 컨볼루션 계산을 진행함. 이 Stride변수는 기존에 한칸씩 넘어가면서 곱셈을 진행했다면, 만일 이값을 2로 설정했을시 두칸씩 너머어가면서 곱셈을 진행하게됨.

밑에 그림과 같이 7*7이미지를 3*3 커널로 곱했을때, 기존 공식으로 했을때 아웃풋이미지는 5*5가되지만 Stride 를2로 설정했을시, 아웃풋 이미지 크기는 3*3이 나온다. 공식은 다음과 같다.
Floor함수는 함수안에 값이 소수점으로 나왔을때 제일가까운 정수로 만들어주는 함수이다.
공식 : Floor((N+2P-F)/S + 1) * Floor((N+2P-F)/S + 1)
Pooling Layers
표현되는 크기를 줄이고, 계산속도를 올리기위해서 사용되는 Pooling Layers
Max Pooling

Max Pooling의 예제는 위와같다. 4*4 이미지에서 2*2로 Max Pooling을 진행할경우 색영역마다 제일 큰 숫자를 뽑아서 2*2로 바꿔주면된다. 이렇게 할경우 특정 영역마다 feature를 자동으로 뽑는 역할을 한다. max pooling의 특징은 하이퍼파라미터(max pooling의 크기)는 존재하지만, learning phase가 존재하지않는다(max pooling의 크기는 고정적이기 때문).

만일 5*5 인풋이미지에서 3*3 Max Pooling을 진행한다면 컨볼루션 곱셈과 같이 한칸씩 이동하면서 연산을 진행하면된다.
Average Pooling
위와같이 Max Pooling은 색 영역에서 가장 큰 값을 가져온것에 반해. Average Pooling은 색 영역에서 평균 값을 가져온다.

아웃풋 이미지 크기의 공식은 다음과같다
F - Filter Size
S - Stride
만일 인풋 이미지 차원이 (Nh * Nw * Nc) 일경우
Floor( (Nh - F)/S + 1) * Floor( (Nw - F)/S + 1) * Nc
Why Convolutions
Parameter sharing : A feature detector that's useful in one part of the image is probably useful in another part of the image.
즉,컨볼루션은 어떤 특징을 감지하는 부분이 다른 이미지에서도 똑같이 작동할것이라는 의미
Sparsity of connections : In each layer, each output value depends only on a small number of inputs
즉, 컨볼루션은 계산할때 전체 영역에 영향을 주는것이 아닌 특정영역에만 영향을주고 다른 영역에는 영향을 안준다
Case Study
LeNet - 5
손글씨를 구별하기위해 만들어진 모델. GrayScale 이미지를 구별하기 위해 만들어졌으므로 제일처음 input의 3차원값은 1이다.1. stride가 1인, 6개의 5*5필터를 사용, padding이 없으므로 출력결과는 28*28*62. Average Poolling방법으로 한번더 축소3. stride가 1인 16개의 5*5 필터를 적용.4. Average Pooling적용5. 5*5*16 은 400이므로 이를 Fully Connect(FC)로 연결

AlexNet
Alex Krizhevsky의 이름을 따서 만든 모델. 해당 모델 논문의 1저자라고한다.
[2012, ImageNet classification with deep convolutional neural networks]

해당논문에서는 224*224*3이미지를 인풋으로한다고 써져있지만 실제로는 227*227*3으로 하는게 맞다고함.
LeNet과 유사한점이많지만 훨씬더 커진 버전. LeNet에는 약 6만개의 파라미터가 있는반면, AlexNet에는 6천만개의 파라미터가 존재함.
VGG-16
[2015, Very deep convolutional networks for large-scale image recognition]
더욱더 많은 파라미터를 가진반면에 단순한 네트워크 구조를 가지고있음. 해다아 모델은 약 1억3천8백만개의 파라미터를 가지고있음.
CONV = 3 * 3 filter, s=1, Same Convolutional
MAX-POOL = 2*2 filter, s=2
그림에서의 [CONV n] * 2라는 뜻은 n개의 필터를 2번 적용했다라는 의미이다.
VGG-16에서의 16은 16개의 레이어에 가중치가 있음을 나타냄(CONV갯수+FC갯수 = > 13+3 =16)

Pooling Layer는 높이와 너비를 줄이고, Convolutional Layer는 깊이를 늘리는데. VGG에서는 이렇게 줄이고 늘리는걸 비율적으로 잘적용해서 매력적인 모델이라고함(내가 맞게 이해한건진 모르겠음)
ResNets
Inception Network Motivation
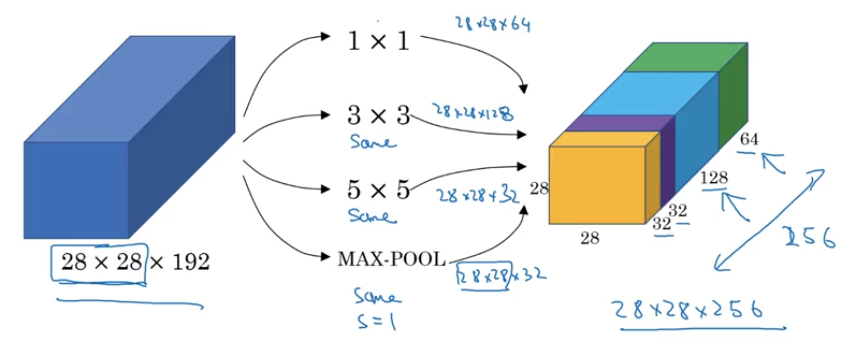
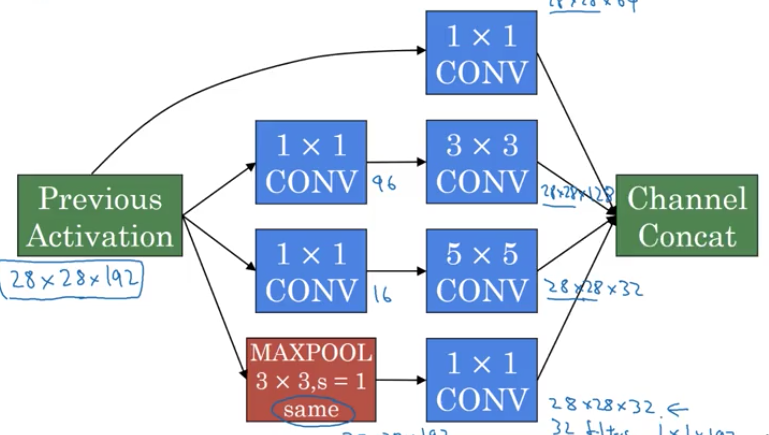
여러가지 필터를 곱해서 다 합치는 방식 컨볼루션이든 풀링이든 계산한뒤 하나의 layer에서 다 합치면된다. 하지만 영상에서 소개하듯이 이 방식의 단점이 계산량면에서 다른방식보다 우월하지않다는점. 예를들어서 5*5*32 컨볼루션 필터를 곱한다고 했을때 총 필요한 곱셈 횟수는

28*28*32*5*5*192로 총 약 1억2천만이라는 수가 나온다. 언제나 그렇듯 이러한 방식은 좋다 나쁘다를 판단할수가없다 딥러닝쪽에선 모델마다 어떤 문제에 대해서 다 장단점이 있기때문.
Data Augmentation
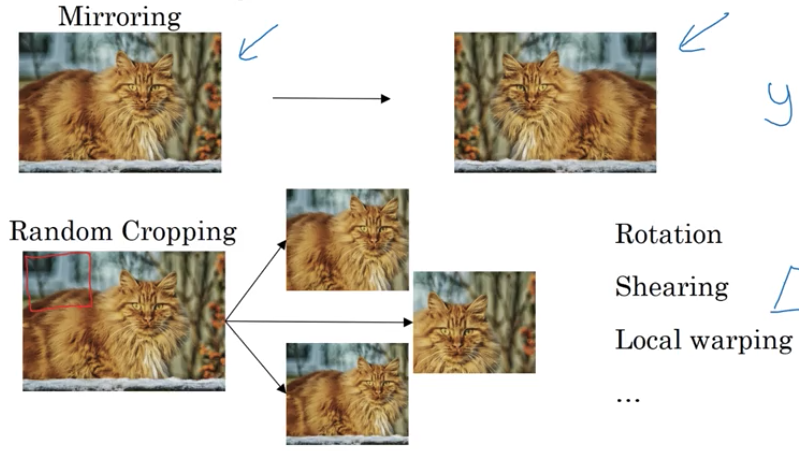
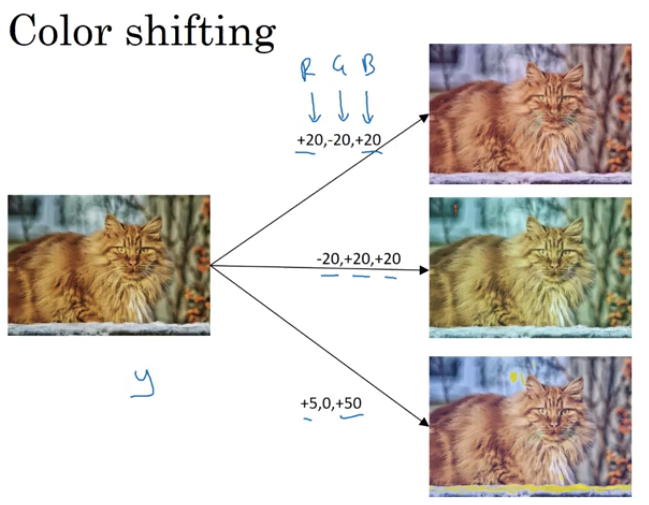
데이터 증강이란. 특정분야에서 데이터를 얻기힘들때 사용하는 기법이다. 예를들어서 고양이 사진이 부족했을때 밑 이미지와같이 좌우반전을 시켜서 데이터를 만들어내는것도 데이터 증강방식중에 한가지이다. 또한 특정 부위를 잘라서 이미지를 만드는것도 방법중 한가지이다. 많이 쓰이는 방법은 Rotation(이미지 회전), Shearing, local warping등이 있다.
Object Localization
우리는 앞에서 CNN을 이용해서 이것이 고양이인지 강아지인지를 판별할수있는 모델들을 알아보았다. 여기서 이제 추가로 의문점은 "고양이와 강아지가 분류가 되었다면 사진에서 어디에 위치하고있는가?" 를 답하기위해선 Object Localization이 필요하다.

우리가 앞에서 이것이 차사진인지 사람사진인지를 구분하는 문제는 - Image classification
이것이 차사진으로 구분하고 추가로 차가 어디에있는지까지 답을 얻는문제는 - Classification with localization
단순히 사물위치를 탐지하는 문제 - Detection
이번절에서는 두번째문제인 Classification with Localization 문제를 푸는 방법을 알아보자

기본적으로 CNN에서 이것이 차량사진인지 사람사진인지 구분하기위해선 맨 마지막 layer를 softmax를 거쳐서 특정 index 값이 커질때 대응하는 사물을 답안으로 했다면. Localization까지 하기위해선 label자체를 다음과같이 설정한다.
[사물이 있는가, 사물위치Bx, 사물위치By, 사물위치Bh, 사물위치Bw, 사물class1, 사물class1]
로된다.
여기서 Bx, By는 예시에서 차량이 있는 위치의 중점이고, Bh, Bw는 사물이 어느정도 크기인지 알려주는 파라미터이다.
Convolutional Implementation of Sliding Windows[이해하려고 노력중...ㅇㅁㅇ]
위에서는 사진중에 '한대'의 차량을 탐지를 했다면, 여러대의 차량이 있을경우엔 어떻게 탐지를 해야할까?
사실 여기서 뭔가 굉장히 다른 알고리즘이 쓰일줄알았지만 기본적인 방법은 이해하기 쉬웠다. 단순히 이미지위에 새로운 윈도우를 겹쳐서 탐지하는 방법이다. 이를 Sliding Windows라고한다.
기존에 학습방법은 동일하게 진행하고 sliding windows에 대해서는 2차원에 대해서만 학습을 진행한다.
- 기존 CNN학습

- Sliding Windows 학습

아래와 같이 자동차가 인식할때까지 반복적으로 windows를 옮기면서 인식을 진행함. 하지만 이러한 방법에는 단점이있음. 다음 강의에서 계속해서 설명

One-Shot Learning
얼굴인식 프로그램을 만들때 필요한기법. 딥러닝 알고리즘은 트레이닝 데이터가 하나만 있는 경우 제대로 작동하지않음. One-Shot Learning은 하나의 트레이닝 데이터로 분류를 할수있는것이다.
예시로 얼굴인식 프로그램을 들었는데.
직원이 4명있는 회사에 얼국인식프로그램을 만들때. 사람얼굴 데이터는 많지않아서 딥러닝 네트워크를 학습시키기엔 부족하다. 또한 새로운 직원이 들어올때마다 새롭게 학습을 시키기엔 많은 리소스가 들기때문에 비현실적이다. 이럴때 One-Shot Learning을 이용하여 이러한 문제점을 극복한다.
One-Shot Learning은 이제 Similarity function을 사용한다.
어떤 두 이미지의 차이값을 나타내는 함수를 이용해서, 특정임계값을 넘었을경우엔 "다름", 작거나 같을땐 "같음" 으로 하여 구별한다.
이럴경우엔 새로운 직원이 들어왔을때도 쉽게 구현이된다.

Siamese Network
One-Shot Learning의 과정을 간단하게 설명하면 두장을 동일한 네트워크(동일한 파라미터)를 거쳐 나온 맨 마지막 Layer를 각각 fx1, fx2라고할때. 두개는 모두 벡터값이고, 이 벡터값의 거리를 계산한다. 거리값이 즉 위에서 언급한 특정임계값으로 보면될것같다.

여기서 One-Shot Learning에서 사용하는 네트워크를 Siamese Network라고 한다. 그렇다면 여기서 학습의 목표는 다음과같다
- 네트워크안의 파라미터 값이, 만약 동일한 인물의 사진을 넣어서 fx1, fx2라는 값이 나왔을때 두 벡터 거리값이 최소가되는 파라미터값이 되도록 학습을 시켜야한다. (also, 다른인물이면 두 벡터 거리값이 최대가 되는 파라미터값)
Triplet Loss

Siamese Network는 Triplet Loss라는 손실함수를 쓰는데. 단어뜻 그대로 한번에 세개의 이미지를 항상 보게되는 손실함수이다.
여기서 세가지 이미지는
- Anchor Image(A) - 제일 기본이 되는 이미지
- Positive Image(P) - Anchor Image와 같은 사람이지만 다른 이미지
- Negative Image(N) - Anchor Image와 다른 사람
A와 P는 거리가 가까워야하고, A와 N은 거리가 멀게끔해줘야함. 즉,
||f(A) - f(P)|| ^ 2 <= ||f(A) - f(N)|| ^ 2
하지만 여기서 f(A) - f(P) 와 f(A) - f(N)이 둘다 0으로 되어도 식은 성립되기 때문에, 모든 이미지의 인코딩(네트워크 출력층)이 동일하게 설정되지않도록 해줘야함.
그래서 이를위해 식뒤에 알파값을 더해줌. 이 알파값은 Margin이라고한다.
따라서, 마진값(0.2라고 가정)을 추가하게된다면 예제로
||f(A) - f(P)|| ^ 2 + a <= ||f(A) - f(N)|| ^ 2 라는 식이있다면 f(A) - f(P)이 0.5라고할때, f(A) - f(N)은 0.7보다 같거나 커야한다(위그림처럼)


세장 이미지를 넣어서 지속적으로 학습. 삼중 Loss function이 minimum하게 만들어준다면 동일인물한테는 작은 벡터 거리값이, 다른인물한테는 큰 벡터값이 계산되는 네트워크를 만들수가있음. 특히 이 세장의 이미지를 학습할때 랜덤으로 고르게되면 ||f(A) - f(P)|| ^ 2 + a <= ||f(A) - f(N)|| ^ 2 이 공식이 너무 쉽게 달성되기때문에 최대한 학습되게 어렵게끔해줘야함. 즉, ||f(A) - f(P)|| ^ 2 값과 ||f(A) - f(N)|| ^ 2 유사한 걸로 넣어줘야함.
Face Verification and Binary Classification
그렇다면 One-Shot Learning 얼굴인식 프로그램이 어떻게 구성되는지 알아보자.

인풋에는 두장의 사진이 들어가고, label은 이 두장의 사진이 같은지 다른지를 1,0으로 표현한다.
두장의 사진을 넣게되면 예시로 네트워크 F(x)에끝은 128개 노드가 있는 layer(F(xi), F(xj))가 나온다고했을때, 이 두개의 벡터를 로지스틱 회귀(128개 노드가 있는 layer두개가 합겨지는 원)에 넣어서 시그모이드 함수를 거쳐서 라벨을 비교한다.
What is neural style transfer?
원본이미지(C)를 특정이미지의 스타일(S)을 결합시켜 새로운 이미지(G)가 나오게끔하는 기술

Style transfer Cost Function
Style transfer의 cost function은 두가지 요소를 평가한다.
- 첫번째로, 원본이미지의 콘텐츠(건물, 물건등)가 생성된 이미지안의 컨텐츠와 얼마나 유사한지 -> Jcontent(C, G)
- Content Cost Function
- 두번째로, 적용시키고자하는 스타일과 생성된 이미지의 스타일이 얼마나 유사한지 -> Jstyle(S, G)
- Style Cost Function

학습할때 G는 랜덤으로 생성을해도된다. 학습을 진행하면 위의 공식에서 J(G)가 제일 최소값이 되는 지점을 찾는다. 랜덤으로 생성된 이미지(G)는 다음과같이 변화된다(위에서 아래로 학습되는과정).

Content Cost Function
이미학습된 컨텐츠 이미지 분류 네트워크(예시로, VGG)를 이용해서, 만약에 생성된 이미지와 원본 이미지의 특정 레이어가 유사하다면 이는 두개 사진에 들어있는 컨텐츠가 유사하다는걸 유추할수있음

Style Cost Function
이해중... 어렵다 ㅠㅠ
