
Deeplearning.ai 코스 세번째 강의 시작... 이번엔 ML프로젝트에 필요한 지식들을 배운다고한다.
TP&TN&FN&FP
True Positive(TP) - 양성인데, 양성으로 제대로 검출된것
True Negative(TN) - 음성인데 음성으로 제대로 검출된것
False Positive(FP) - 음성인데 양성으로 잘못 검출된것
False Negative(FN) - 양성인데 음성으로 잘못 검출된것
Accuracy & Error Rate & Precision & Recall & ROC
- Accuracy = (TP + TN) / 전체 데이터 수 (정확도)
- Error Rate = (FP + FN) / 전체 데이터 수 (오류도)
- Precision = TP / (TP + FP) (정밀성, Positive로 예측한 애들중에, 실제 Positive의 비율)
- Recall = (TP) / P (민감도, Positive에서 실제 Positive로 예측한 비율)
Improving your model performance
- You can fit the training set pretty well : Low avoidable bias
- The tarining set performance generalizes pretty well to the dev/test set

Carrying out error analysis
만약 고양이와 개 사진을 분류하는데 개사진을 분류하는데에 성능이 떨어질경우 오류분석을 진행한다
Error analysis:
- Get ~ 100 mislabeled dev set examples
- Count up how many are dogs
만일 잘못분류된 100개의 dev set중 5개만 개 사진일경우. 개발자가 이 개 사진만 오류를 수정하기위해서 시간을 투자한다면 결과론적으로 5%의 성능을 향상시키게됨. 하지만 전체적으로 봤을땐 10% 오류에서 9.5% 성능개선만 이뤄진거임. 즉, 비효율적인 시간투자로 결론이나게됨.
따라서 5장만 보는것이 아닌 95장을 보는것이 더 효율적이게 된다.
Evaluate multiple ideas in parallel
- Ideas for cat detection:
- Fix pictures of dogs being recognized as cats
- Fix great cats being misrecognized
- Improve performance on blurry images
오류 분석을 실행하는데에는 먼저 dev set이나 development set에서 잘못 레이블된 데이터들을 찾고, 데이터 분석을진행(어떤 데이터셋이 False Positivee, False Negative인지등등 그 수량은 얼마나있는지등). 좀더 효율적인 방향으로 개선을 진행.
복습차 다시 Bias & Variance 개념정리
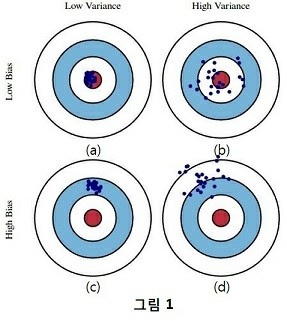
Bias - 참 값들과 추정 값들의 차이
Variancce - 추정 값들의 흩어진 정도를 의미
(a) - low bias & low variance
(b) - low bias & high variance (Over-fitting, Train Data set에 과적합)
(c) - high bias & low variance (Under-fitting, Test Data set에 학습이 덜됨)
(d) - high bias & high variance
Addressing Data Mismatch
- Carry out manual error analysis to try to understand difference between training and dev/test sets
- 학습 데이터와 개발 데이터 사이에 어떤 데이터 특성이 다른지를 이해할 것
- Make training data more similar; or collect more data similar to dev/test sets
- 알고리즘 상에서 문제가 발생하는 개발 데이터에 조금 더 적합한 학습 데이터를 조금 더 수집할 것
학습데이터와 개발 데이터간의 차이점이 발생하면 이를 Data Mismatch라고 한다.
강의에서 예시로. 학습데이터 셋은 조용한 곳에서 녹음된 음성파일인것에 비해 개발 데이터 셋은 자동차 엔진음이 섞인 음성파일일경우엔 두 데이터셋의 환경이 다르므로 이는 Data Mismatch이다.
Transfer Learning(전이학습)
머신러닝의 많은 모델은 적용하려는 데이터가 학습할 때의 데이터와 같은 분포를 가진다고 가정으로 했을때 효율적. 이미 잘 훈련된 모델이 있고, 특히 해당 모델과 유사한 문제를 해결할수있을때 Transfer Learning을 사용한다. 또는 유사한 문제지만 학습 데이터가 부족할때 전이학습을 사용!
When transfer learning makes sense
- Task A and B hav the same input X
- You have a lot more data for Task A than Task B
- Low level features from A could be helpful for learning B
Multi-task Learning
When multi-task learning makes sense
- Training on set of tasks that could benefit from having shared lower-level features
- 여러 문제들의 하나의 저레벨 특성을 공유할 때
- Usually: Amount of data you have for each task is quite similar
- 데이터가 비슷할떄
- Can train a big enough neural network to do well on all the tasks
- 거대한 작업 세트들을 하나의 큰 신경망으로 한번에 학습 시키려고 할 떄
다중 작업 학습보다는 전이학습이 더 많이 쓰이고있다고함.
End-to-End deep learning
End to End Deep Learning이란 인간이 아무런 feature를 추출해서 분석할 필요없이 input만 넣어주면 자동으로 y출력이 나오는것을 의미한다. 이는 딥러닝 분야에 큰 기여를했다. 예시로 다음과같다
어떤 음성파일이 있을 때 원래 방법으로는 다음과 같이 긴 과정이 필요했지만
X(Audio, Input) -> Feature Extracting -> ML -> Words -> Y(Transcript, Output)
End to End deep learning을 적용시키면 끝과 끝 과정만 필요하게 된다
X(Audio, Input) -> Y(Transcript, Output)
- end-to-end 딥러닝은 자료처리 시스템 / 학습시스템에서 여러 단계의 필요한 처리과정을 한번에 처리합니다. 즉, 데이터만 입력하고 원하는 목적을 학습시키는 것
- 이는 기존의 처리 파이프라인 중 일부를 대체할 수 도 있습니다. 다만, end-to-end 딥러닝을 사용하기 위해서는 엄청나게 많은 양의 데이터가 필요합니다.
- 하지만 end-to-end 딥러닝이 만능은 아닙니다. 단계를 나눠서 학습 시키는 것이 효율적일 때도 있습니다. 효율적인 이유는 아래와 같습니다.
- 복잡한 문제를 분리하여 각각의 간단한 문제로 바꿉니다.
- 데이터의 정보가 각각의 작업에 더 적합되게 사용됩니다.
- 따라서, 순수 end-to-end 딥러닝 보다는 문제를 쪼개서 해결하는 것이 좋습니다.
End-to-End deep learning의 장단점
- 장점
- 데이터로 하여금 말을 하게합니다. 즉, 사람의 선입견 영향을 덜 받습니다.
- 사람의 중간 요소 설계를 줄일 수 있습니다.
- 단점
- 방대한 양의 데이터가 필요합니다.
- 잠재적으로 유용하고 사람의 손으로 만들어진 중간 요소를 완전 배제합니다. 이는 데이터가 적을 때 효율적인 특정 지식을 사용할 수 없습니다.
- 따라서, end-to-end 딥러닝을 사용하기전에 항상 어떤 작업을 하려고 하는지, 특히, 지도학습에서 x, y 를 어떻게 연관지을 것인지를 생각해야합니다.
- 또한, 학습하기 위한 데이터가 충분한지도 고려해야합니다.
'Data > Data Science' 카테고리의 다른 글
| [deeplearning.ai] Sequence Models (0) | 2020.10.30 |
|---|---|
| [deeplearning.ai] Convolution Neural Network (0) | 2020.09.18 |
| [HMM] Hidden Markov Models (0) | 2020.08.28 |
| [deeplearning.ai] Coursera 필기정리 4 (0) | 2020.08.27 |
| [deeplearning.ai] Coursera 필기정리 3 (1) | 2020.07.11 |



