본 게시글은 "실전 카프카 개발부터 운영까지" 책을 읽으면서 중요하다라고 생각되는 내용을 정리한 글입니다.
책에 대한 정보는 https://product.kyobobook.co.kr/detail/S000001932756 에서 보실수 있습니다.
(중요) 내용이 정확하지 않거나, 누락된게 있을수 있습니다.

카프카의 주요 특징
- 높은 처리량과 낮은 지연시간
- 아마 카프카를 선택하는 가장 큰 이유
- 높은 확장성
- 미래를 생각(서비스 규모가 커질것을 예상)해서 확장이 편리함
- 고가용성
- 내구성
- 장애가 나도 과거의 메세지들을 불러와 재처리가능함
- 개발 편의성
- 메세지를 전송하는 역할(producer)와 메세지를 가져오는 역할 컨슈머(consumer)가 완벽하게 분리되어이쏙 서로 영향을 주지도 않음.
- 개발할때 producer, consumer에 대해서 집중해서 개발 가능
- 운영 및 관리 편의성
- 카프카는 중앙 메인 데이터 파이프라인 역할을 하기때문에 운영 및 관리하기가 편함
사용 사례
- 넷플릭스

- 우버

- 머신러닝 분야 활용 사례
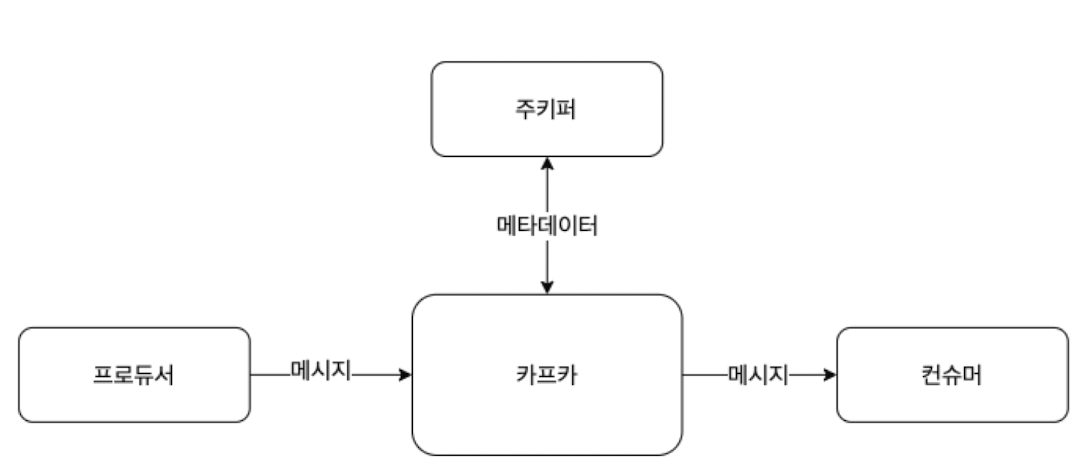
카프카의 기본 구성
주키퍼 - 카프카의 정상 동작을 보장하기 위해 메타데이터를 관리하는 코디네이터
프로듀서 - 카프카에 데이터를 만들어서 주는 쪽
컨슈머 - 카프카에서 데이터를 빼내서 소비하는 쪽
카프카 - 데이터를 받아서 전달하는 데이터 버스 역할
책이 2021년도 책이라서 그렇고, 현재는 주키퍼가 없는 구조로 이뤄져있다고함.
제일 먼저 토픽을 생성해야함 아래와같은 명령어로 생성가능
/usr/local/kafka/bin/kafka-topics.sh --bootstrap-server peter-kafka01.foo.bar:9092 \
--create --topic peter-overview01 \
--partitions 1 \
--repliacation-factor 3
그런다음 컨슈머와 프로듀서를 실행해서 카프카를 통한 메세지 주고받기를 함
카프카에서는 아래와같은 요소가 추가로 알아둬야함
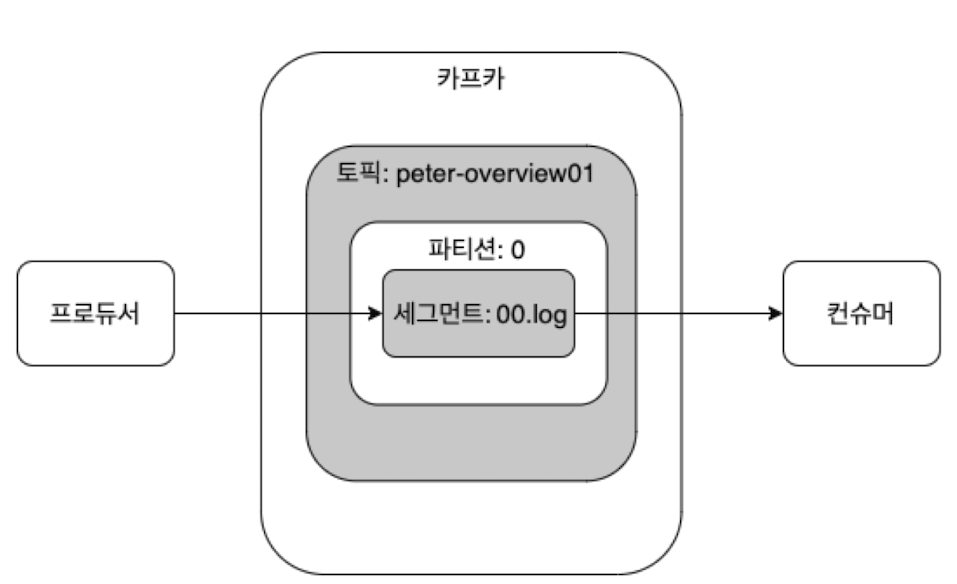
- 브로커(broker) - 카프카 앱이 설치된 서버 또는 노드를 말함
- 토픽(topic) - 카프카는 메세지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유함
- 파티션 - 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것을 의미함
- 세그먼트(segment) - 프로듀서가 전송한 실제 메시지가 브로커의 로컬 디스크에 저장되는 파일
- 메세지 or 레코드 - 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각을 뜻함
replication
위의 명령어에서 replication-factor란 메세지를 여러 개로 복제해서 카프카 클러스터내 브로커들에 분산시키는 동작을 의미. 즉, 장애를 위한 옵션으로 보여짐. 다만, 해당 값이 높아 질수록 안정성은 높아지겠지만, 그만큼 리소스를 많이 사용하게 됨.
보통은 개발할때는 1개, 운영환경에서는 2~3개로 함. (2개는 약간의 유실을 허용하는 환경)
partition
하나의 토픽이 한번에 처리할 수 있는 한계를 높이기 위해 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만든것을 파티션이라고 함.
주의해야 할 점은, 파티션은 언제든지 수를 늘릴수 있지만, 반대로 줄일수는 없음. 따라서 초기에 적당히 작게 설정해뒀다가, 상황에 맞게 늘려가는 방식으로 쓴다고함.
상황은 LAG이라는 요소를 보고 결정한다고함. LAG이란 (프로듀서가 보낸 메세지 수) - (컨슈머가 가져간 메세지 수)를 의미.
그다음, 세그먼트는 파티션구조 아래에 존재함. 전체적인 구조는 아래와같게됨
'Data > Data Engineering' 카테고리의 다른 글
| [ELK] k8s에 Elasticsearch(multinode) + Kibana 구축하기 (1) | 2023.12.19 |
|---|---|
| [filebeat] 로그 파일 새로운 라인만 수집되게 하는법 (0) | 2023.12.07 |
| [ELK] kibana-elasticsearch (WIP) (0) | 2023.04.03 |
| [Airflow] Task Was the task killed externally? + 아무런 로그없이 죽는 현상 해결 (0) | 2022.12.01 |
| [Grafana] Slack Alert 메세지 커스텀마이징 (0) | 2022.11.20 |



