목차
반응형

Normalization(정규화), Standardization(표준화), Regularization모두 다 머신러닝 또는 딥러닝에 학습에 효율적 또는 Overfitting을 피하기 위해서 나온 기법들이다.
Normalization, Standardization은 모델에서 특정 Feature가 값이 큰경우 해당 feature가 큰영향을 끼치는것을 방지하기위해서 적용하는 기법이다.
Normalization
- 값의 범위를 0~1사이의 값으로 바꾸는 것
- 방법은 다양함
- MinMaxScaler - 최대 최소값을 이용한 방법
- Standard Score
- Student's t-statistic
- Studentized residual
- Standardized moment
- Coefficient of variation
en.wikipedia.org/wiki/Normalization_(statistics)
Standardization
- 값의 범위를 평균 0, 분산 1이 되도록 변환
- Standard Scaler 또는 z-score normalization이 있음
- 정규분포를 표준정규분포로 변환하는 것과 같음
- -1 ~ 1 사이에 68%가 있고, -2 ~ 2사이에 95%가 있고, -3~3사이에 99%가 있음
- -3~3이외는 Outlier일 확률이 높음
realblack0.github.io/2020/03/29/normalization-standardization-regularization.html
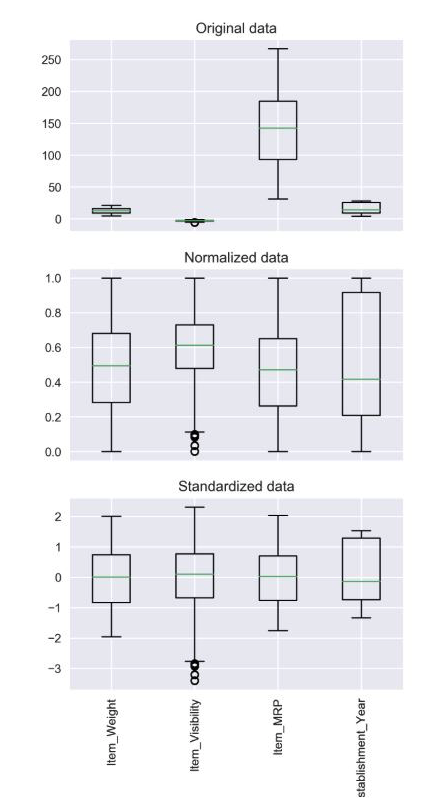
밑의 그림은 Normalization, Standardization을 적용한뒤의 데이터들의 변화이다
Regularization
- 머신러닝, 딥러닝에서의 Weight를 제약을 걸어서 Overfitting이 안되게끔하는 방법
- 대표적으로 L1, L2 Regularization, Drop-Out이 있음
반응형
'Data > Data Science' 카테고리의 다른 글
| [Pytorch] Autoencoder Base code (0) | 2020.11.29 |
|---|---|
| [Pytorch] Basic Neural Network (0) | 2020.11.23 |
| [Kaggle] Kaggle에 pyspark 설치하기 (0) | 2020.11.04 |
| [deeplearning.ai] Sequence Models (0) | 2020.10.30 |
| [deeplearning.ai] Convolution Neural Network (0) | 2020.09.18 |



