반응형

Apply
pyspark 에서 udf성격을 띄는 pandas function 이다.
# 한 컬럼만 적용할 경우
def stars(values):
if values >= 95:
return 3
elif values >= 85:
return 2
else:
return 1
df.values.apply(stars)
# 여러 컬럼이 필요할 경우
def stars(df):
if df.country == 'canada':
return 3
elif df.score >= 95:
return 3
elif df.score >= 85:
return 2
else:
return 1
df.apply(stars, axis='columns')Map
위처럼 함수를 사용하지않고 한줄의 코드로도 작성이 가능하다
# 만일 한 column에서 평균 값을 뺀 결과를 얻고싶다면...
# df Dataframe
#+------+
#|score |
#+------+
#| 1|
#| 2|
#| 3|
#+------+
avg_score = df.score.mean()
result = df.score.map(lambda x: x - avg_score)
# 사실 이 연산은
# df.score - df.score.mean() 이랑도 같은 결과가나온다
"""
결과는
-1
0
1
"""value_counts()
특정 column에서 해당 값이 얼마나 나왔는지 확인용 함수
"""
데이터프레임 df에 특정컬럼(score)안에
1
1
1
3
3
3
2
2
가 있다고 할때
"""
df.score.value_counts()
"""
1 -> 3
3 -> 3
2 -> 2
score별로 개수를 세어줄수가있다
"""groupby()
특정 그룹을 이뤄서 연산을 할때 사용하는 함수
# 특정 그룹의 한개의 컬럼만 계산하고싶을떄
df.groupby('column1')['column2'].mean()
# 특정 그룹의 여러개 컬럼을 계산해야할때(ex. 어떤건 카운트 어떤건 평균값이 필요할때
df_after = df.groupby('column1').agg({'column2':'count', 'column3':'mean'})
# df_after가 dataframe을 보면 index들이 좀 이상한 위치에 있는데 이걸 바로잡으려면
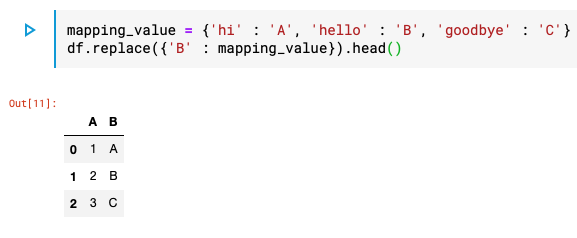
df_after.reset_index()replace()
Dataframe에서 특정 값들을 변경하고싶을때
- 변경전

- 변경후
반응형
'Data > Data Analysis' 카테고리의 다른 글
| [Pyspark ] pivot 함수 사용방법 (0) | 2020.11.18 |
|---|---|
| [Pyspark] groupBy 개수 중복제거 countDistinct (0) | 2020.11.12 |
| [SQL] RANK(), ROW_NUMBER(), DENSE_RANK() (0) | 2020.08.05 |
| [SQL] ARRAY_CONTAINS 함수 (0) | 2020.07.20 |
| [Pyspark] UDF 함수에 parameter값 추가 (0) | 2020.05.08 |



