반응형

Kafka?
카프카는 Stream Processing(실시간 데이터처리)관련 툴이며, 취업관련 플랫폼 회사인 LinkedIn에서 개발했다고한다. 이 툴도 미국의 대기업에서는 다 사용중이라고한다(Apple, Netflix, AirBnB etc...).
여담이지만, 최근 데이터 엔지니어 직군 공고들을 보면 대부분 Kafka에 대한 지식 소유자는 우대사항에 포함되어있다. 그만큼 요즘에는 중요하게 사용되는 Stream Processing 도구인것같다.
Kafka 장점?
- 확장성 - 하루에 1조개의 메세지 처리 가능, Petabyte의 데이터를 처리 가능
- 메시지 처리 속도 - 2MS
- 가용성 - 클러스터 환경에서 작동
- 데이터 저장 성능 - 분산처리, 내구성, 장애 허용(fault tolerant)
Kafka 구조
카프카는 여러가지 요소로 구성되어있다
- Topic
- 하나의 채널(폴더)개념. 데이터 스트림이 어디에 Publish될지 정하는데 쓰임.
- Kafka Partition, Kafka Offset
- 토픽안에 담기는 메세지들은 파티션으로 나뉘어지고, 파티션안에서는 Offset단위로 나뉘어짐
- 카프카의 메시지는 Byte의 배열, String, JSON, Avro사용. 메세지 길이는 제한이없으나 성능을 고려해 작게 유지하는것이 좋다고함
- 토픽별로 데이터는 사용자가 지정한 시간만큼 저장(Retention Period)

topic - partition - offset 구성
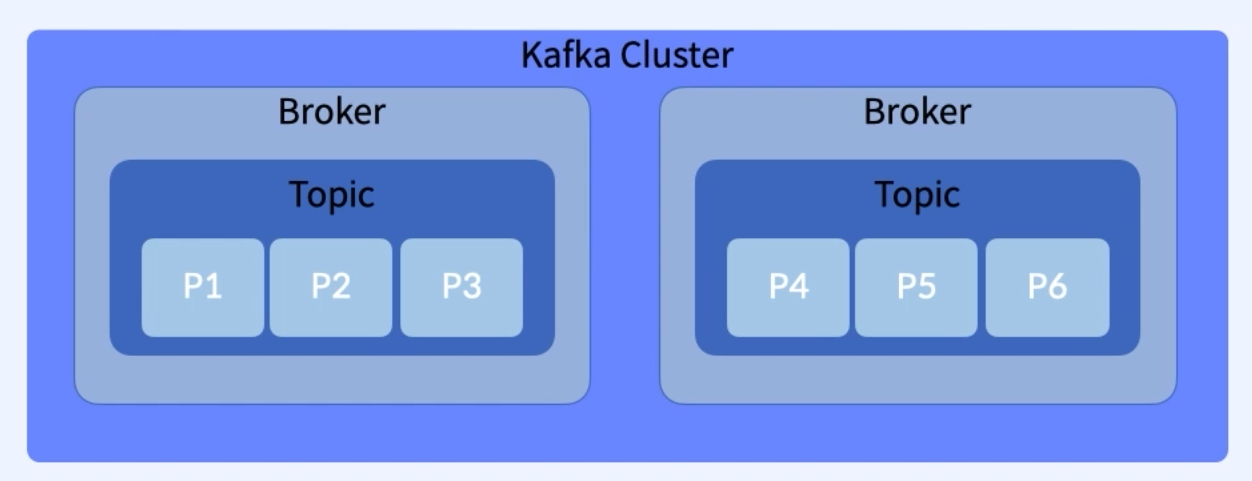
- Kafka Cluster, Kafka Broker
- Kafka Topic은 여러 Broker에 걸쳐서 생성
- Kafka Broker는 Kafka Server 이기도함
- Kafka Cluster는 여러개의 Kafka Broker(Server)를 가질 수 있음
- Producer가 메세지를 게시하면 Round-Robin방식으로 파티션에 분배
- Round-Robin - 동일한 크기로 순서대로 우선순위를 부여
- Replication Factor 라는 성질을 갖고있는데, 완벽하게 이해는 못한것같지만, 여러 Broker가 존재할때, 그중 한개가 망가져도 복구능력을 갖는걸 말하는것같다. 뭔가... K8s에서 replicasets을 보는것같다.
- Kafka Producer, Kafka Consumer, Kafka Consumer Group
- Producer는 메세지를 보내는 역할, Consumer는 받는 역할, 받는 역할은 그룹을 이룰수있음(Kafka Consumer Group)
- Producer는 카프카 토픽으로 메시지를 게시하는 클라이언트 어플리케이션. 메시지를 어느 파티션에 넣을지 결정(Key)이가능. Key를 지정안하면 Round Robin방식으로 각 파티션에 할당.
- Consumer Group을 지정하지 않으면 새로운 Consumer Group에 배정
- Consumer Group안의 두 Consumer는 같은 파티션으로부터 동시에 메시지를 받을 수 없다
- Zookeeper
- 클러스터 관리
- Topic 관리
- 파티션 리더 관리
- 브로커들 끼리 서로를 발견할 수 있도록 정보전달
- Zookeeper도 분산처리중 일부이기 때문에 다운이될경우 시스템 전체에 영향을 줄수있음
반응형
'Data > Data Engineering' 카테고리의 다른 글
| [Airflow] 인자값 전송 및 Task raise exception (0) | 2022.03.10 |
|---|---|
| [Flink] Flink 정보 정리 (0) | 2022.02.19 |
| [Airflow] 관련 정리 (0) | 2022.02.02 |
| [Pyspark] 소소한 지식 (pyspark, RDD, 캐싱, 파티셔닝, 최적화) (1) | 2022.02.01 |
| [Airflow] 잡다한 트러블 슈팅 (0) | 2021.11.12 |



