
HDFS(Hadoop Distributed File System)
단일장비가 아닌 클러스터에 분산 저장을 하기때문에 큰 용량파일을 저장 할 수가 있음.
Replication Factor로 인해, 여러 데이터 노드에 정보값을 복사 저장을해서, 문제가 발생해도 데이터를 불러읽을수있음.
...
Pyspark?
요즘 대부분 우리가 알고있는 IT대기업들은 모두 pyspark를 사용중에있음(Netflix, Uber, MS ...).
빅데이터의 세가지문제로 출발해서 Pyspark를 만들게되었는데. 이 세가지 문제를 3V 라고도하는데 다음과같다.
- Velocity - 데이터의 생성되는 속도 증가
- Volume - 데이터의 크기 증가
- Variety - 데이터의 다양성 증가
위와같은 문제를 제일 처음겪은곳은 당연히 "Google"이다. 강의에서는 "The Google File System"이라는 논문을 보여줬다. 자세한 내용은 아래 링크를 타서 보면된다.
https://static.googleusercontent.com/media/research.google.com/ko//archive/gfs-sosp2003.pdf
해당 논문을 보고 감명을 받은 "Yahoo"기업은, Hadoop이라는 데이터 분산처리 시스템을 만들었다.

여기서 Spark는 hadoop의 연산엔진을 개선한 프로젝트다

여러 사람들의 질문들을 보면 "개인컴퓨터에 spark를 설치했지만 pandas보다 느리다" 라는 질문들이 꽤있다. 이것은 Spark가 "확장성"을 고려했기 때문이다.
- 확장성을 고려했기 때문에, 특정 파일크기까지는 Pandas가 빠를수도 있지만, 매우 큰 파일(약 40GB)가 넘어가면 Pandas는 메모리 부족 현상이 발생하게 된다. 하지만 Spark는 아무리 큰 파일이더라도 오류없이 빠르게 데이터를 처리 할 수가 있다.
- Pandas와 Spark의 차이는 다음과같다
- 여기서 Lazy Execution은 spark를 사용하다보면 createOrReplaceTempView함수는 굉장히 빨리 끝나지만, show(), count()등 계산이 필요할때는 상대적으로 오래걸린다. 즉, 계산이 필요한 작업에만 연산이 진행된다
| Pandas | Spark |
| 1개의 노드 | 여러개의 노드 |
| Eager Execution - 코드가 바로바로 실행 | Lazy Execution - 실행이 필요할때까지 기다림 |
| 컴퓨터 하드웨어에 제한을 받음 | 수평적 확장이 가능 |
| In-Memory 연산 | In-Memory 연산 |
| Mutable Data | Immutable Data |
RDD(Resilient Distributed DataSet)
RDD를 이해하면 Spark를 90% 이해하는거라는데...! (직역: 탄력적인 분산 데이터셋)
SparkContext로 특정 데이터를 불러읽는것이 RDD형태.
RDD는 다음과같이 5가지의 성질을 갖고있음
- 데이터 추상화
- 데이터는 클러스터에 흩어져있지만 하나의 파일인것 처럼 사용이 가능하다
- Resilient & Immutable (탄력적이고 불변한 성질)
- 데이터가 여러군데서 연산이 되는데, 이중 하나가 망가질경우? 즉, Immutable하면 이러한 상황에서 복원이 가능
- 네트워크 장애 & 하드웨어 문제 등등
- 변환과정중에서 매번 RDD의 정보를 저장하고있음
- 데이터가 여러군데서 연산이 되는데, 이중 하나가 망가질경우? 즉, Immutable하면 이러한 상황에서 복원이 가능
- Type Safe
- 컴파일시 Type을 판별할 수 있어 문제를 일찍 발견할 수 있다
- sparkSQL를 사용하거나 다른용도를 쓸때 문법이 잘못된경우 오래 기다리지않고 그때그때 바로 에러문이 출력됨
- 컴파일시 Type을 판별할 수 있어 문제를 일찍 발견할 수 있다
- Unstructured / Structured Data
- Unstructured - 로그, 자연어 관련
- Structured - DataFrame, csv 등등
- Lazy Evaluation(게으른 연산)
- RDD에(Spark Operation)는 두가지 연산만 제공됨. Transformation, Action이 있는데, Action을 할때까지는 Transformation을 실행하지않음
왜 RDD를 쓸까?
- 유연하며
- 짧은 코드로 할 수 있는게 많다
- Lazy Evaluation으로 인해 더 고민하게 되고, 시간을 단축하여 개발에 집중할수있음
Pyspark Storage Level

pyspark를 작업할때, 때때로 여러번 사용해야하는 데이터에 대해서는 cache()라는 함수를 사용했었는데, 정확하게 내부에서는 어떻게 돌아가는지 몰랐다.
이러한 여러작업을 반복할시 캐싱해놓는 방법이 두가지가 있는데 하나는 cache()함수고 다른하나는 persist()함수이다. 이 둘의 차이는 다음과 같다.
Cache
- 디폴트 Storage Level사용
- RDD: MEMORY_ONLY
- DF: MEMORY_AND_DISK
Persist
- Storage Level을 사용자가 원하는대로 지정 가능
temp.persist(StorageLevel.MEMORY_ONLY)
temp.persist(StorageLevel.MEMORY_ONLY_SER)그리고 캐싱을 푸는방법은 나같은 경우에는 unpersist()함수를 사용했었다
Shuffle을 일으킬 수 있는 작업들
Shuffle이 일어나면 연산속도에 영향을 준다. 결과로 나오는 RDD가 원본 RDD의 다른 요소를 참조하거나, 다른 RDD를 참조할때 발생함
- Join 류
- GroupByKey
- ReduceByKey
- ComebineByKey
- Distinct
- Intersection
- Repartition
- Coalesce
Shuffle을 발생하는것을 최소화하려면 Partitioning이 필요함(효율적으로 사용하기 위해서는 cache, persist로 캐싱을 해줘야함, 안그러면 계속해서 shuffle이 일어남)
- 디스크에서 파티션하기
- partitionBy()

- 메모리에서 파티션하기
- repartition() - 파티션의 크기를 줄이거나 늘리는데 사용됨
- coalesce() - 파티션을 줄이는데 사용됨
Catalyst & Tungsten
스파크는 쿼리를 돌이기 위해 두가지 엔진을 사용. 각각 Catalyst & Tungsten

Catalyst
- Logical Plan을 Physical Plan으로 바꾸는 일
- 분석: DataFrame객체의 relation을 계산, 칼럼의 타입과 이름 확인
- Logical Plan최적화
- 상수로 표현된 표현식을 Compile Time에 계산
- Predicate Pushdown: join&filter -> filter & join
- Projection Pruning: 연산에 필요한 컬럼만 가져오기
- 이러한 과정을 코드상으로 보고싶다면 아래와같이 explain함수를 활용하면 된다
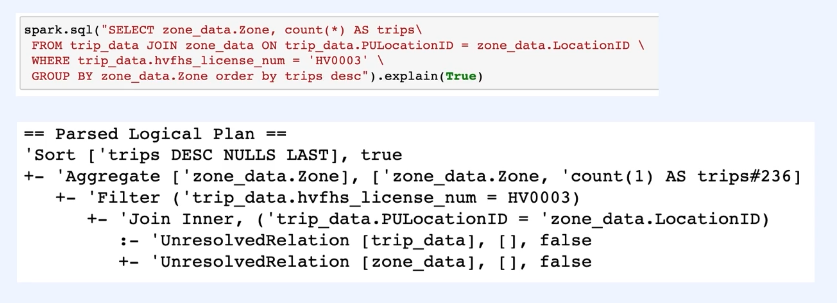
Tungsten
- Physical Plan이 선택되고 나면 분산 환경에서 실행될 Bytecode가 만들어지게된다 - 이 프로세스를 Code generation이라고 부른다
- 스파크 엔진의 "성능 향상"이 목적
- 메모리 관리 최적화
- 캐시 활용 연산
- 코드 생성
'Data > Data Engineering' 카테고리의 다른 글
| [Kafka] Kafka 정리 (0) | 2022.02.05 |
|---|---|
| [Airflow] 관련 정리 (0) | 2022.02.02 |
| [Airflow] 잡다한 트러블 슈팅 (0) | 2021.11.12 |
| [SnowFlake] Tableau에 SnowFlake ODBC 설치(MacOS) (0) | 2021.10.13 |
| [Scala] Scala 언어 기초공부 - 중첩for문 (0) | 2020.12.14 |



