반응형

Clustering
비지도학습 머신러닝 기법중 하나
클러스터링 종류
- Hard Clustering - 한 개체가 여러 군집에 속할수 없는 군집화 방법
- Soft Clustering - 한 개체가 여러 군집에 속할수 있는 군집화 방법
-
- Partitional Clustering - 전체 데이터의 영역을 특정 기준에 의해 동시에 구분하는 군집화 방법. 각 개체들은 사전에 정의된 개수의 군집 가운데 하나에 속하게 됨
- 대표적으로 K-Mean 군집화
- Hierarchical Clustering - 개체들을 가까운 집단부터 차근차근 묶어나가는 군집화 방법. *덴드로그램을 생성함
- 덴드로그램 → 계층적 군집에서 클러스터의 개수를 지정해주지 않아도 학습을 수행할 수 있는 것은 개체들이 결합되는 순서를 나타내는 트리 형태의 구조

- Self-Organizing Map - 뉴럴넷 기반의 군집화 알고리즘
- Spectual Clustering - 그래프 기반의 군집화 알고리즘

클러스터링 평가 방법
Dunn Index
- 군집 간의 거리는 멀고, 군집 내 분산은 작을수록 좋은 군집화 결과
- 분자 - 군집 간 거리의 최소값
- 분모 - 군집 내 요소간 거리의 최대값

Silhouette (실루엣 지표)
- a(i) → i번째 개체와 같은 군집에 속한 요소들 간 거리들의 평균
- b(i) → i번째 개체와 다른 군집에 속한 요소들 간 거리들의 평균을 군지마다 각각 구한뒤, 이중 가장 작은값을 취함

클러스터링 알고리즘 종류

DBSCAN - Density-Based Spatial Clustering of Applications with Noise
KMeans 클러스터링은 개체들의 거리를 이용하여 클러스터를 나누는것에 반해, DBSCAN은 데이터 포인트가 세밀하게 몰려있는 밀도가 높은 부분을 군집화 하는 방식
Python Sklearn DBSCAN파라미터
- eps → 데이터간의 최대거리
- min_samples → 중심객체에서 최대거리까지 포함되는 객체 개수
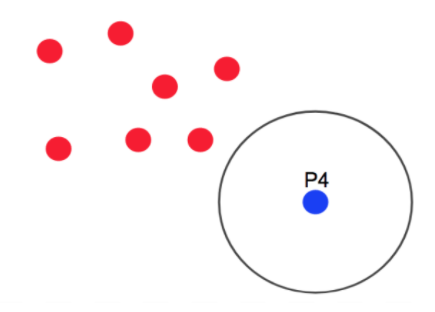
DBSCAN 작동 과정

- 임의의 데이터를 선정하고 min_samples에 해당되는 점을 중심객체로 선정

- min_samples조건을 충족하지못하면 외곽객체로 선정

- 만약 겹치는 객체가 생기면 동일 군집으로 판단

- 모든 객체가 조사될때까지 반복
- 외곽, 중심객체에도 속하지않는 객체는 노이즈로 처리
장점
- 클러스터 개수 정의 불필요
- 노이즈 처리에 강함 (노이즈객체를 따로 분류)
- U자형, H형 모양을 띄는 데이터 분포도 잘 군집화처리가 가능
단점
- 많은 연산이 필요하여 결과처리에 속도가 느림
- 2~3차원까지의 데이터는 연산속도가 그나마 받쳐주지만, 고차원의 데이터를 처리할때는 연산량이 급증하는 단점
- 주변거리 하이퍼파라미터 e값을 정하기가 어려움

참조
반응형
'Data > Data Science' 카테고리의 다른 글
| [EECS 498-007, Lecture5] Activation Function이 필요한 이유 (0) | 2021.05.20 |
|---|---|
| [Pytorch] torch.nn layer 함수 정리 (추가정리중) (0) | 2021.05.03 |
| [ML] 짜투리정리 (0) | 2021.02.14 |
| [머신러닝] LGBM, XGBoost, GBM (2) | 2021.02.03 |
| [Gradient Descent] 경사하강법 (0) | 2021.01.13 |



